
Music influences a person on a neurological level. It impacts the temperament and conduct of a person [1]. It influences the function of the brain and human actions including, relieving stress, depression symptoms, as well as enhancing cognitive and motor functions, spatial-temporal learning and neurogenesis which is the capacity of the brain to create neurons [2]. The lyrics of the song play a major role in increasing this influence of music. For instance, songs with ‘prosocial’ lyrics may make you more empathic and could lead to long-term changes in attitudes and behavior for the better [3,4].
The problem arises in creating the lyrics of these songs. Artists face the problem of deciding topics to create songs on. The problem is further intensified in selecting the most unique, catch words which if added, could create more powerful lyrics for the songs. These powerful lyrics with the right combination of other music features (liveliness, loudness, speech ness, etc.) could create hit songs in the future.
A solution for this problem was proposed by this study which analyzed the lyrics of the billboard songs over the past 10 years. This study was carried out using the ‘Hot 100 collection of Billboard songs’ dataset from ‘data world’. This dataset contains every weekly Hot 100 singles chart from 2009-2019. Each row of data represents a song and the corresponding position on that week’s chart.
The lyrics of the songs in the dataset were analyzed to find the most important words in each song using TF-IDF technique of natural language processing.
The use of the different type of important words in songs captured the preference of users, being motivated to listen to the most popular hits of the time. This important word’s analysis provided a deeper understanding on the choice of words used by the most popular artists.
Furthermore, a unique bag of evergreen words used in song’s lyrics from this dataset for the period of 2009-2019 was also found. The lyrics made using these evergreen words could be used to create more powerful songs in the future. This hypothesis of including evergreen words in the song lyrics to create more powerful songs was validated by most desired genre ‘Dance Pop’ most beloved artist Katy Perry’s songs lyrics.
Another research named ‘The Bob Dylan Encyclopedia, New York, Continuum’, [6] was focused on repeated use of ‘Ecstacy’ in rap lyrics and it’s changing reference over the decade from 1996. The study found that the increase in the number of raps was directly proportionate to the increasing use of ‘Ecstacy’ among secondary school teenagers. It also considered changes in songs ciphered with positive, ambiguous, or negative messages about the use of this drug.
In a study Ronce [7], discussed the evolution of Dylan’s song lyrics throughout 50 years of his career as an artist by using quantitative and qualitative analyses methods. It analyzed change in his word selection and theme selection explored in his songs in terms of qualitative and quantitative changes respectively. It was found that lyrics of the most popular songs could capture sociocultural changes across generations. A word-count method was used to compute the percentages of words belonging to various psychosocial categories including positive emotion, religion, social processes. Sociocultural studies captured word selection possibly indicating (Dylan’s generation) generational changes in American culture. Further examination produced the correlations between the year of album release and the 10 LIWC categories of words. The correlations provided the fact that years were directly proportionate to the type of words used over time.
In another research conducted by Napier et al., [8], the songs were grouped together by year in which they were produced and their tone scores were averaged for each year. The standard deviation and standard error were calculated for every averaged tone of every year. This was followed by conducting two tests to spot a linear relation between features, year and specific tone from the lyrics of the respective year. It was used to examine the relationship between two continuous variables. Furthermore, the linear dependency between these variables was validated using linear regression technique. This research concluded that some of Pearson’s correlation coefficients (anger, disgust, fear, and conscientiousness) were considered of having strong positive correlations throughout. This analysis indicated the tonal change of popular music lyrics through generations. Over the years, an increment in some sentiments such as anger, disgust, fear, sadness, tentativeness and conscientiousness and decrement in sentiments such as joy, analytics, confidence and openness was found.
This hypothesis was validated by the most desired genre’s most beloved artist. A bar chart was visualized to find the most desired genre, i.e., ‘Dance Pop’. The most beloved artist, i.e., ‘Katy Perry’ according to the dataset was found using Pie chart visualized over the top 10 artists of the Dance Pop genre. The lyrics of the songs created by Katy Perry were visualized using word cloud. This word cloud gave an overview of words used in her songs. These words thus found were validated using the bag of unique evergreen words to prove this hypothesis.
Furthermore, a cluster map was plotted to find the correlation between different music features.
Genius API follows a collection of protocols, routines and tools for extraction of songs from genius.com web site. Lyrics extractor initially needed a Google API key and an Engine Id of Google custom Search JSON API. An API key is a distinctive selector that is used to validate a user, developer or calling application to an API. The custom search JSON API allows you to build websites and programs to fetch and show search results from Google custom search procedurally, it requires a unique authenticator key to initiate the search process (lyrics extraction). This API was integrated with GENIUS API as mentioned above to extract the lyrics of the specified song from the lyrics-extractor library.

TF-IDF is defined as a statistical technique which evaluates the significance of the respective word in a document within a collection of documents (Dataset). Its applications include in the field of machine learning (Natural Language Processing) and automated text analysis for the computation of scores of word features [11].
It is computed by the multiplication of two metrics namely term frequency and inverse document frequency. The term frequency (TF) of a word in a document is the frequency of a particular word in the document.
The inverse document frequency (IDF) of the word across a set of documents is used to find the respective word’s significance in the entire corpus (Dataset). It’s closeness to zero is directly proportionate to the frequency of the word in the corpus. It is computed as the logarithmic value of the quotient of the total number of documents and the frequency of documents containing the word by taking the total number of documents.
This produces the TF-IDF score of a word in a document. The score is directly proportionate to the importance of the word in the particular document.
The TF-IDF features thus obtained was used for carrying out the analysis of song lyrics keywords used in lyrics of the songs present in the dataset.
The lyrics for each song were extracted using lyrics extractor API in python.an API is defined a set of functions and procedures which allows the creation of applications capable of accessing the features or data of an operating system, application, or other services.
Lyrics extraction was followed by finding the most important word of each song in the dataset for broadening analysis on the importance of words in creating lyrics of a song.
Initially only words were selected using the ‘re’ module of python, followed by normalizing the words into lowercase. The words were then converted into their base forms using stemming. Stemming is the process of decreasing a word to its word stem by affixing to suffixes and prefixes or to the roots of words known as a lemma.
This led to the stop words removal from dataset using natural language toolkit library in python. Useless words (data) are referred to as stop words in the dataset.
The corpus of lyrics thus obtained was used for calculating term frequency-inverse document frequency. The sum of the TF-IDF scores was used for word feature selection, selecting the important words in the lyrics in the dataset. The words features having sum greater than threshold value (0.2) computed across the dataset were selected to be used for further analysis and visualization processes.
The most important word features (top 50 words) used in lyrics of songs for each year from 2009-2019 were visualized using ‘nltk’ and ‘matplotlib’ library in python. For the year 2010, the most important words were ‘like’, ‘wanna’, ‘go’, ‘yeah’, ‘oh’, ‘love’ etc. This was followed by ‘girl’, ‘run’, ‘yeah’, ‘baby’ etc in 2011 and ‘love’, ‘feeling’, ‘tonight’, ‘like’, ‘talk’ in 2019 (Figure 3) and so on. It was also found how the lyrics have changed in the short span of 10 years, as the result of the change in listening preferences of billboard chart listeners.

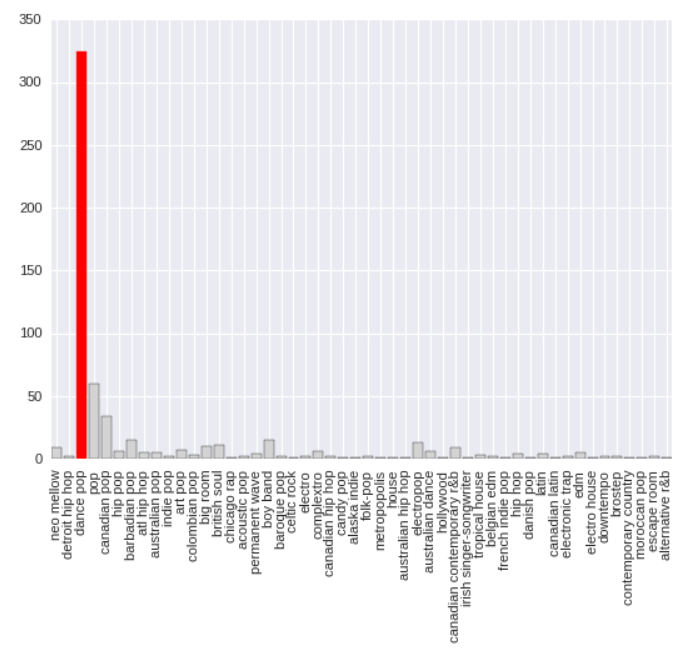
Analysis on genres of songs and their respective artists revealed that the most popular genre according to the frequency of songs was found to be ‘Dance Pop’ (Figure 4).
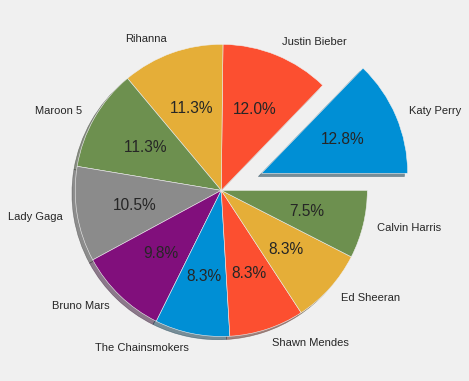
Further it was found that the most beloved artist among the top ten artists was found to be Katy Perry producing 12.8 % of the total billboard songs (Figure 5). On analysis of Katy Perry’s songs, it was found that maximum songs produced belonged to the ‘Dance Pop’ genre.
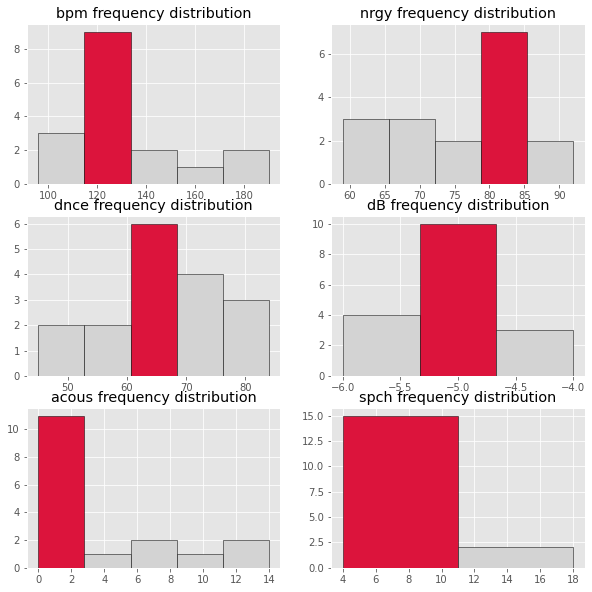
Katy Perry’s songs revealed frequency range of (110-130), (80-85), (60-70), (80-85), (-5.5 – -4.5), (0-2), (4-11) of beats per minute, energy, dance, decibels, acoustic ness, speech ness features respectively (Figure 6).
A cluster map is created using hierarchical clustering techniques to find the amount of similarity or correlation between two features. It was also found that the features energy and loudness (dB) are highly correlated with a positive score of \(+0.54.\) This correlation concluded the fact that people doing workouts listen to loud music to achieve efficiency in their workout.
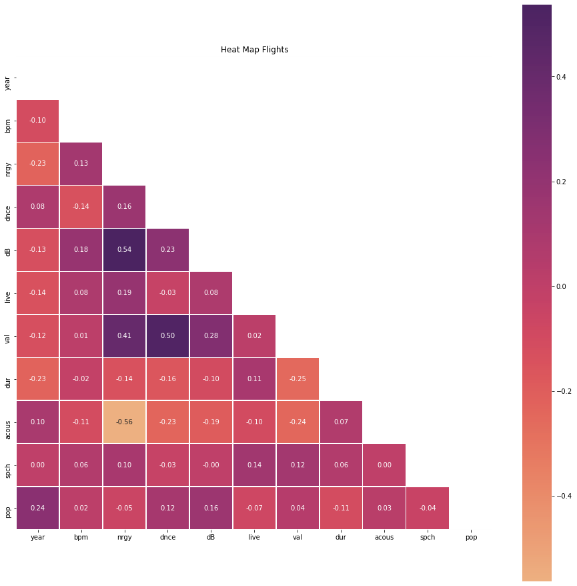
Acoustics (the characteristic of a space for determination of transmission of sound through it) are not correlated with energy, showcased with a value of \(-0.56\) on the correlation matrix. Liveliness or the probability of live audience listening to the song is not at all correlated with the duration of the song \(+0.11.\) This means that liveliness or the moment a song tries to create does not depend on the length (duration) of the song. It can be felt within the song, during the entire song or not at all in the song.
Word cloud also known as a text cloud or a tag cloud is based on simple technique, i.e., the boldness and the size of the word is directly proportionate to the frequency of the word in the specific document. They are generally used for analyzing customer feedback/review and identifying new SEO (Search Engine Optimization) song lyrics keywords to target. The word cloud was created using the ‘wordcloud’ and ‘pandas’ library and was visualized using ‘matplotlib’ library in python. The ‘wordcloud’ is a library licensed by MIT. It also includes ‘DroidSansMono.ttf’ apache licensed, a true style font developed by Google [13].
The word cloud generated from Katy Perry’s, most beloved artist according to billboard (2009-2019) dataset was visualized to give overall view of the song lyrics keywords used in her songs lyrics as well as for validating the most frequent terms of the word cloud with the most frequent terms from the evergreen words distribution plot. It was found that words like ‘love’, ‘night’, ‘friday’ (also appearing in the top 50 evergreen words) used in Katy Perry’s songs were also the most catchy, loveable and desired words for the listeners during the period of 2009-2019 (Figure 8).
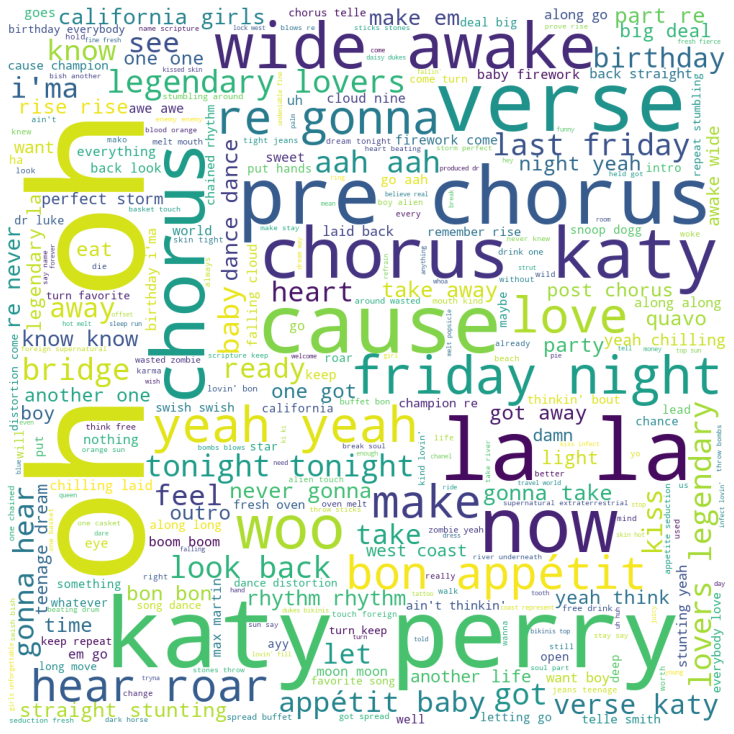
These words found in her songs motivated the audience to listen more to these songs. This also led to an increase in the audience for these ‘Dance Pop’ songs, thereby increasing the number of hits of her songs.
Sentiment analysis is deciphering, analyzing and classifying emotions (like happy, sad, neutral) within textual data using analytical techniques. In methodological terms, sentiment analysis detects polarity within the text, documents, comments etc. It assists organizations in distinguishing an individual’s sentiments towards products or services like garments, music etc.
Understanding the emotions through people’s point of view is vital as people will communicate their conclusions even more uninhibitedly now in light of digitization. In this way, by analyzing the feedback given by the people, brands will tailor their products and services regarding the people’s necessities [14]. The ‘vaderSentiment’ library was used to find the polarity scores of the songs [15].
The data frame containing ‘positive’, ‘negative’, ‘neutral’, ‘compound’ scores was plotted as a bar plot using ‘pandas’ library to visualize the sentiment present in her song’s lyrics (Figure 9). This also helped in highlighting the type of sentiment favored by the audience in song’s lyrics

The popularity of the songs based upon the no of unique evergreen words was plotted and compared with the popularity of songs based on the no of YouTube views (Figure 10). The plot showed that 12 out of 17 songs of the dataset’s most beloved artist Katy Perry followed a direct proportionality trend. This trend showed that the number of YouTube views were directly proportional to the no of important words present in the songs. These important words were also present in the unique bag of evergreen words. For instance, a song ‘Dark horse’ had 83 unique evergreen words in its lyrics and had a ‘very popular’ likeability (Figure 11). Similarly, another song ‘birthday’ had only 3 evergreen words and had a ‘popular’ likeability. This analysis found that the increase in the number of evergreen words made the lyrics more powerful and in turn increased the number of views of the song (popularity).
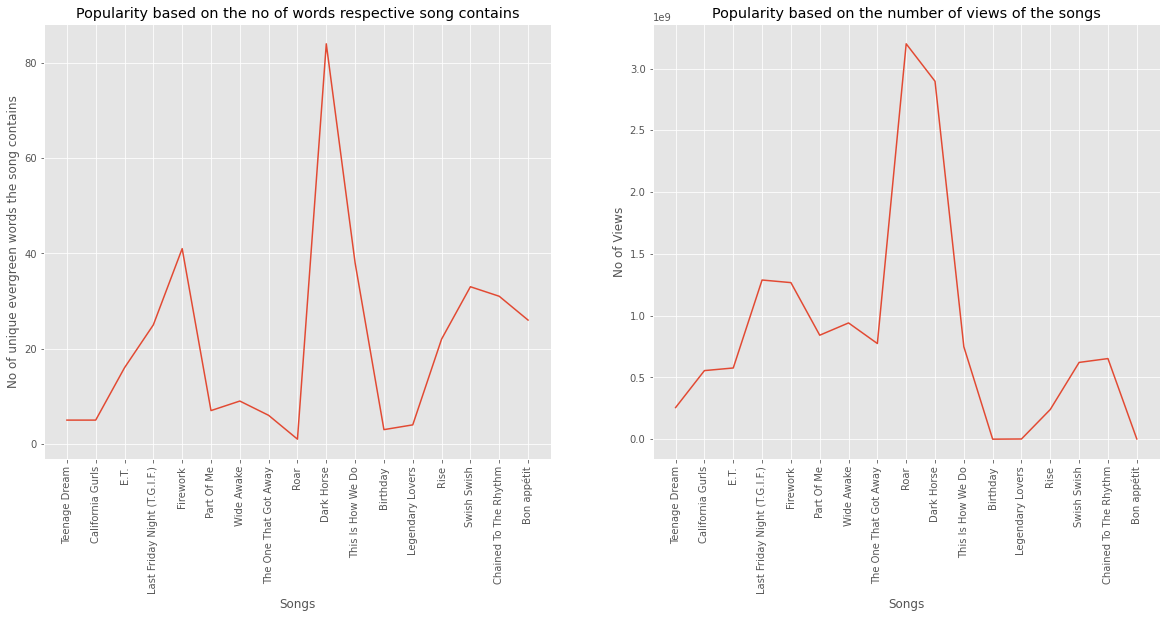
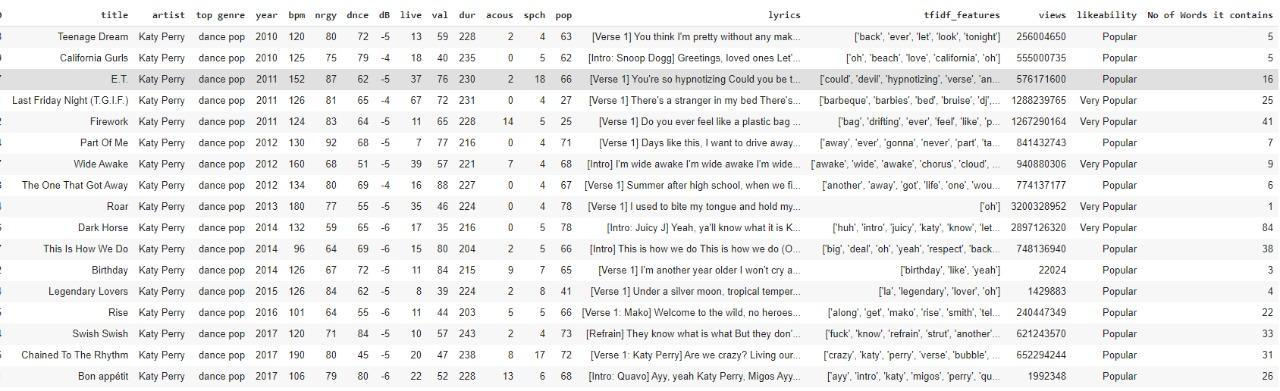
This analysis was also found useful in deciding the genre for creating songs on, which was ‘Dance Pop’. The words from the unique bag of evergreen words also could be used in deciding the title on which songs could be created to increase the no of hits of the songs. For example ‘last friday night’ song by Katy Perry was among the most popular songs. The song lyrics keywords ‘friday’ and ‘night’ are also present in bag of unique evergreen words. Similarly a song ‘love me like you do’ by Ellie Goulding also contains the evergreen words ‘like’, ‘love’, ‘you’ gained large no of hits and was loved by the audience. The title and the category could also be used to capture the sentiment loved by the people (love and like here). The title of the song could be further used to investigate the emotions special to that topic, for example, the ‘Friday’ could be used to capture the specialty of that day. Similarly, a word ‘like’ could be used to capture the feeling of being liked or liking something in the songs.
The analysis in future could deepen its understanding of songs using the tonal sequence while analyzing the popularity of the respective song. Furthermore, an increment in the number of songs in the dataset could help in improving the accuracy of this analysis to create more powerful song’s lyrics in the future.
