
Approximation theory serves as a vital conduit linking abstract analysis with practical applications and is primarily concerned with the approximation of functions through simpler structures such as sequences of positive linear operators [1]. The renowned theorem of Korovkin [2] supplies simple yet potent criteria regarding the convergence of such operators to the identity. While classical approximation theory is contingent upon ordinary convergence, numerous sequences encountered in practice display oscillatory behavior or are devoid of traditional limits which necessitates the employment of more flexible convergence methods. Moreover Anastassiou and Gal [3] deliberated on approximation theory with an emphasis on global smoothness preservation as a complement to the study of convergence rates. In a broader context regarding infinite matrices, Sahani et al. [4] recently investigated estimates for the rate of convergence and their applications to infinite series.
To address these constraints the concept of statistical convergence was inaugurated by Fast [5] and Steinhaus [6]. This methodology has discovered profound applications within approximation theory most notably by Gadjiev and Orhan [7] and has been expanded to diverse abstract structures including \(n\)-normed spaces [8] and credibility spaces [9]. Duman and Orhan [10] contributed significantly to statistical approximation via positive linear operators. Beyond these settings the concept has been scrutinized in the context of lacunary ideal convergence in random \(n\)-normed spaces [11] and \(I\)-statistical convergence in 2-normed spaces [12]. Furthermore the interplay between statistical convergence and operator theory has been explored on Fock spaces [13, 14] while Wijsman lacunary invariant statistical convergence was studied by Huban and Gürdal [15]. Additionally Kişi et al. [16] investigated asymptotically lacunary statistical equivalent sequences in generalized metric spaces.
To augment the applicability of this method further generalizations such as weighted statistical convergence have been formulated. Karakaya and Chishti [17] introduced weighted statistical convergence which was subsequently modified by Mursaleen et al. [18] for Korovkin type approximation theorems. Ghosal [19] extended this to the order \(\alpha\). Braha et al. [20] provided results concerning weighted statistical convergence associated with Korovkin and Voronovskaya type theorems. Another pivotal development is the concept of deferred statistical convergence. Agnew [21] originally introduced deferred Cesàro means which established the foundation for this theory. Later Küçükaslan et al. [22] further advanced deferred statistical convergence for sequences in metric spaces.
Notwithstanding these advancements a fundamental limitation persists in that standard convergence theories presume the existence of a unique and classical limit. However within real world systems involving random variables or experimental data classical convergence is frequently an idealization. The concept of rough convergence introduced by Phu [23] resolves this by permitting a degree of roughness \(r\). This notion was subsequently extended to rough statistical convergence by Aytar [24]. Recently Mursaleen et al. [25] examined rough deferred statistical convergence for sequences in neutrosophic normed spaces and highlighted the versatility of these methods.
In the realm of probability theory the behavior of random variables introduces an additional layer of complexity. Statistical convergence in probability was inspected by Das et al. [26]. Asymptotic equivalence introduced by Marouf [27] and Patterson [28] compares the relative behavior of two sequences. Akbas and Isik [29] examined asymptotically \(\lambda\)-statistical equivalent sequences of order \(\alpha\) in probability. Recently the concept of rough weighted ideal convergence has been investigated by Aziz and Ghosal [30] in the context of normed spaces. Nevertheless the study of rough asymptotic equivalence in probabilistic function spaces via deferred weighted methods remains an open problem.
The primary motivation of this paper is to bridge this gap by introducing a unified framework known as rough asymptotically deferred weighted statistical equivalence of order \(\alpha\) in probability. We utilize deferred weighted density where \(p=(p_n)\) represents a non-negative weight sequence and \(D_n = (a_n, b_n]\) denotes the deferred interval.
The manuscript is structured as follows. In §2 we define the new concept of rough asymptotic equivalence and analyze its properties. In §3 we establish a rough Korovkin type theorem for positive linear operators. Finally we provide an illustrative example and concluding remarks.
In this section, we establish the rigorous theoretical framework of our study. To address the precision requirements of probabilistic approximation, we first outline our standing assumptions and notation.
Throughout this paper, we adopt the following fixed conventions.
(A1) Let \((S, \mathcal{F}, P)\) be a fixed probability space. We denote the set of all random variables defined on this space by \(\mathcal{M}(S)\).
(A2) To ensure that ratios of random variables are well-defined almost surely (a.s.), we assume that for any sequence of random variables \(Y = \{Y_k\}\) discussed in the context of equivalence, \(P(Y_k = 0) = 0\) holds for all \(k \in \mathbb{N}\).
(A3) Let \(\{a_n\}\) and \(\{b_n\}\) be sequences of non-negative integers satisfying the conditions \(a_n < b_n\), \(\lim_{n\to\infty} b_n = \infty\) and \(a_n < b_n < a_{n+1} < b_{n+1}\). The deferred interval is denoted by \(D_n = (a_n, b_n] = \{k \in \mathbb{N} : a_n < k \le b_n\}\).
(A4) Let \(p = (p_k)\) be a sequence of non-negative real numbers such that \(p_k > 0\) for all \(k\). We define the weighted sum over the deferred interval as \(W(D_n) := \sum\limits_{k \in D_n} p_k\) and strictly assume that \(W(D_n) \to \infty\) as \(n \to \infty\).
(A5) For any subset \(K \subseteq \mathbb{N}\), the weighted cardinality restricted to the deferred interval is denoted by \(|K \cap D_n|_p := \sum\limits_{k \in K \cap D_n} p_k\).
We now introduce the definition of deferred weighted density of order \(\alpha\).
Definition 1. Let \(\alpha \in (0, 1]\) be a fixed real number. The deferred weighted density of order \(\alpha\) of a subset \(K \subseteq \mathbb{N}\) is defined by \[\delta_{N_p}^\alpha(K) := \lim_{n \to \infty} \frac{|K \cap D_n|_p}{[W(D_n)]^\alpha} = \lim_{n \to \infty} \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in D_n \cap K} p_k,\] provided that the limit exists.
Standard asymptotic equivalence mandates that the ratio of two sequences converges precisely to unity. However, to model systems with inherent measurement limitations, we introduce a roughness degree \(r \ge 0\). The following definition constitutes the core framework of this paper.
Definition 2. Let \(r \geq 0\) be a non-negative real number and \(\alpha \in (0, 1]\). Two sequences of random variables \(\{X_k\}\) and \(\{Y_k\}\) are said to be rough asymptotically deferred weighted statistical equivalent of order \(\alpha\) in probability, denoted by \(X \overset{r-PDS_{N_p}^\alpha}{\sim} Y\), provided that for every \(\varepsilon > 0\) and every \(\delta > 0\), the set of non-conforming indices has deferred weighted density zero of order \(\alpha\). Explicitly, this means \[\lim_{n \to \infty} \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in K_n(\varepsilon, \delta, r)} p_k = 0,\] where the set of exceptional indices is defined as \[K_n(\varepsilon, \delta, r) := \left\{ k \in D_n : P\left( \left| \frac{X_k}{Y_k} – 1 \right| \geq r + \varepsilon \right) \geq \delta \right\}.\]
Remark 1(Comparison with Existing Notions).The definition of rough asymptotically deferred weighted statistical equivalence generalizes several existing convergence notions. By specializing the parameters \(r\), \(\alpha\), \(p_k\), and the interval \(D_n\), we recover classical concepts as detailed in Table 1.
| Concept | Roughness | Order | Weights | Interval | Reference |
| Our Definition | \(r \ge 0\) | \(\alpha \in (0,1]\) | \(p_k\) | \(D_n=(a_n, b_n]\) | This paper |
| Weighted Stat. Equivalence | \(r = 0\) | \(\alpha = 1\) | \(p_k\) | \(D_n=(0, n]\) | Mursaleen et al. [18] |
| Deferred Stat. Equivalence | \(r = 0\) | \(\alpha = 1\) | \(p_k \equiv 1\) | \(D_n=(a_n, b_n]\) | Küçükaslan [22] |
| Stat. Equivalence of order \(\alpha\) | \(r = 0\) | \(\alpha \in (0,1]\) | \(p_k \equiv 1\) | \(D_n=(0, n]\) | Akbas & Isik [29] |
| Classical Asymp. Stat. Equivalence | \(r = 0\) | \(\alpha = 1\) | \(p_k \equiv 1\) | \(D_n=(0, n]\) | Patterson [28] |
Motivated by the specific error tolerance required in approximation theory, we introduce the concept of minimal roughness degree.
Definition 3. The minimal roughness degree between two sequences \(X\) and \(Y\), denoted by \(\tilde{r}(X, Y)\), is defined as the infimum of all roughness tolerances for which the equivalence holds: \[\tilde{r}(X, Y) := \inf \left\{ r \geq 0 : X \overset{r-PDS_{N_p}^\alpha}{\sim} Y \right\}.\]
If the set is empty, we define \(\tilde{r}(X, Y) = \infty\).
The following proposition addresses the finiteness and algebraic properties of this degree, as required for rigorous consistency.
Proposition 1. Let \(X\) and \(Y\) be sequences of random variables.
(i) If the ratio sequence \(X/Y\) is bounded in probability in the sense that for every \(\delta > 0\), there exists \(M > 0\) such that the set of indices where \(P(|X_k/Y_k| > M) \ge \delta\) has deferred weighted density zero, then \(\tilde{r}(X, Y)\) is finite.
(ii) The equality \(\tilde{r}(X, Y) = 0\) holds if and only if \(X\) and \(Y\) are asymptotically deferred weighted statistically equivalent of order \(\alpha\) (in the classical sense with \(r=0\)).
(iii) For any non-zero real constant \(c \neq 0\), the equality \[\tilde{r}(cX, cY) = \tilde{r}(X, Y) ,\] holds.
Proof. (i) Let \(\delta > 0\) be given. Since the ratio is bounded in probability, there exists a constant \(M > 0\) such that the set \(A = \{k \in D_n : P(|X_k/Y_k| > M) \ge \delta\}\) satisfies \(\delta_{N_p}^\alpha(A) = 0\). Thus, for any fixed \(\varepsilon > 0\) and for any \(r \ge M+1\), we have \[P\left( \left| \frac{X_k}{Y_k} – 1 \right| \ge r + \varepsilon \right) \le P\left( \left| \frac{X_k}{Y_k} \right| > M \right) < \delta, \qquad (k \notin A).\] Hence, for this \(r\), the exceptional index set \[K_n(\varepsilon, \delta, r) = \left\{ k \in D_n : P\left( \left| \frac{X_k}{Y_k} – 1 \right| \ge r + \varepsilon \right) \ge \delta \right\},\] is contained in \(A\), and therefore has deferred weighted density zero. This proves that \(X \overset{r-PDS_{N_p}^\alpha}{\sim} Y\) for some finite \(r\), and consequently \(\tilde{r}(X, Y) < \infty\).
(ii) If \(\tilde{r}(X, Y) = 0\), then for every \(\varepsilon > 0\), the rough equivalence holds with \(r=0\). This implies that for any \(\varepsilon > 0\) and \(\delta > 0\), the set \[K_n(\varepsilon, \delta, 0) = \left\{ k \in D_n : P\left( \left| \frac{X_k}{Y_k} – 1 \right| \geq \varepsilon \right) \geq \delta \right\},\] has deferred weighted density zero, which is the definition of exact equivalence. The converse follows from the definition of infimum.
(iii) Observe that \(\left| \frac{cX_k}{cY_k} – 1 \right| = \left| \frac{X_k}{Y_k} – 1 \right|\). The probabilistic events and the index sets \(K_n(\varepsilon, \delta, r)\) remain identical under scalar multiplication. Hence, the infimum over \(r\) is unchanged. ◻
Rough equivalence is monotonic with respect to the roughness degree but, unlike classical equivalence, it is not transitive. Instead, it obeys a specific error propagation law.
Theorem 1. Let \(r_1, r_2 \geq 0\) with \(r_1 < r_2\). If \(X \overset{r_1-PDS_{N_p}^\alpha}{\sim} Y\), then \(X \overset{r_2-PDS_{N_p}^\alpha}{\sim} Y\).
Proof. Let \(\varepsilon > 0\) and \(\delta > 0\). Since \(r_1 < r_2\), we have the strict inclusion of events \[\left\{ \omega : \left| \frac{X_k}{Y_k} – 1 \right| \geq r_2 + \varepsilon \right\} \subseteq \left\{ \omega : \left| \frac{X_k}{Y_k} – 1 \right| \geq r_1 + \varepsilon \right\}.\]
Consequently, the set of non-conforming indices for \(r_2\) is a subset of that for \(r_1\). Since the latter has density zero, so does the former. ◻
Theorem 2. Let \(X, Y, Z\) be sequences of random variables. Assume that the ratio \(Y/Z\) is statistically bounded in probability by a constant \(M > 0\). If \[X \overset{r_1-PDS_{N_p}^\alpha}{\sim} Y \quad \text{and} \quad Y \overset{r_2-PDS_{N_p}^\alpha}{\sim} Z,\] then \[X \overset{r_3-PDS_{N_p}^\alpha}{\sim} Z,\] where the accumulated roughness is \(r_3 = r_1 M + r_2\).
Proof. We utilize the algebraic identity \(\frac{X_k}{Z_k} – 1 = \left(\frac{X_k}{Y_k} – 1\right)\frac{Y_k}{Z_k} + \left(\frac{Y_k}{Z_k} – 1\right)\). Let \(\varepsilon > 0\) and \(\delta > 0\). Define the “good” index sets where the variables behave within bounds as \[\begin{aligned} G_1 &= \left\{ k \in D_n : P\left( \left| \frac{X_k}{Y_k} – 1 \right| < r_1 + \frac{\varepsilon}{2M} \right) > 1 – \frac{\delta}{3} \right\}, \\ G_2 &= \left\{ k \in D_n : P\left( \left| \frac{Y_k}{Z_k} – 1 \right| < r_2 + \frac{\varepsilon}{2} \right) > 1 – \frac{\delta}{3} \right\}, \\ G_3 &= \left\{ k \in D_n : P\left( \left| \frac{Y_k}{Z_k} \right| \le M \right) > 1 – \frac{\delta}{3} \right\}. \end{aligned}\]
By hypothesis, the complements \(G_1^c, G_2^c, G_3^c\) have deferred weighted density zero. Thus, the intersection \(G = G_1 \cap G_2 \cap G_3\) has deferred weighted density one (relative to the full weight). For any \(k \in G\), let \(A_k\) be the intersection of the three high-probability events defined above. By the union bound, \(P(A_k^c) < \delta\). On the event \(A_k\), we have \[\left| \frac{X_k}{Z_k} – 1 \right| \le \left| \frac{X_k}{Y_k} – 1 \right| \left| \frac{Y_k}{Z_k} \right| + \left| \frac{Y_k}{Z_k} – 1 \right| < \left(r_1 + \frac{\varepsilon}{2M}\right) M + \left(r_2 + \frac{\varepsilon}{2}\right) = r_1 M + r_2 + \varepsilon.\]
Thus, for all \(k \in G\), \(P(|X_k/Z_k – 1| \ge r_3 + \varepsilon) < \delta\). This implies the set of non-conforming indices is contained in \(G^c\), which has density zero. ◻
In addition to the density-based statistical equivalence, it is standard to consider a stronger notion based on the summability of probabilities. We now rigorously define rough strong equivalence in this framework, ensuring consistency with the standing assumptions.
Definition 4. Let \(q \in (0, \infty)\) and \(r \ge 0\). Two sequences of random variables \(\{X_k\}\) and \(\{Y_k\}\) are said to be rough asymptotically deferred weighted strong equivalent of order \(\alpha\) in probability, denoted by \(X \overset{r-PDW_{N_p}^\alpha(q)}{\sim} Y\), provided that for every \(\varepsilon > 0\) the limit \[\lim_{n \to \infty} \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in D_n} p_k \left[ P\left( \left| \frac{X_k}{Y_k} – 1 \right| \geq r + \varepsilon \right) \right]^q = 0\] holds.
The following theorem clarifies the hierarchical relationship between strong equivalence and statistical equivalence, justifying the terminology.
Theorem 3. Let \(\alpha \in (0, 1]\), \(q > 0\), and \(r \geq 0\). If \(X \overset{r-PDW_{N_p}^\alpha(q)}{\sim} Y\), then \(X \overset{r-PDS_{N_p}^\alpha}{\sim} Y\).
Proof. Suppose \(X \overset{r-PDW_{N_p}^\alpha(q)}{\sim} Y\). Fix arbitrary \(\varepsilon > 0\) and \(\delta > 0\). Consider the set of exceptional indices defined in Definition 2 as \[K_n(\varepsilon, \delta, r) = \left\{ k \in D_n : P\left( \left| \frac{X_k}{Y_k} – 1 \right| \geq r + \varepsilon \right) \geq \delta \right\}.\] Let us define \(\rho_k(\varepsilon) = P\left( \left| \frac{X_k}{Y_k} – 1 \right| \geq r + \varepsilon \right)\). By definition, for any \(k \in K_n(\varepsilon, \delta, r)\), the inequality \(\rho_k(\varepsilon) \ge \delta\) holds, which implies \([\rho_k(\varepsilon)]^q \ge \delta^q\). We establish the lower bound for the deferred weighted sum as \[\begin{aligned} \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in D_n} p_k [\rho_k(\varepsilon)]^q &\geq \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in K_n(\varepsilon, \delta, r)} p_k [\rho_k(\varepsilon)]^q \\ &\geq \delta^q \cdot \left( \frac{1}{[W(D_n)]^\alpha} \sum\limits_{k \in K_n(\varepsilon, \delta, r)} p_k \right). \end{aligned}\]
As \(n \to \infty\), the left-hand side converges to 0 by the hypothesis of strong equivalence. Since \(\delta^q > 0\) is a constant, the term in the parenthesis (which is exactly the deferred weighted density of \(K_n(\varepsilon, \delta, r)\)) must converge to 0. Thus, we conclude that \(X \overset{r-PDS_{N_p}^\alpha}{\sim} Y\). ◻
In this section, we apply the concept of rough asymptotically deferred weighted statistical equivalence to approximation theory. We establish a Korovkin-type theorem demonstrating that if two sequences of positive linear operators are roughly equivalent on the test functions \(e_i(x) = x^i\) (\(i=0,1,2\)), this equivalence propagates to the entire space of continuous functions with a controlled roughness degree.
Let \(C[0,1]\) be the space of all continuous real-valued functions on \([0,1]\) equipped with the supremum norm \(\|f\|_\infty = \sup_{x \in [0,1]} |f(x)|\). Let \(T_n, S_n : C[0,1] \to \mathcal{M}(S)\) be sequences of positive linear operators.
Theorem 4. Let \(\{T_n\}\) and \(\{S_n\}\) be sequences of positive linear operators. Under the standing assumptions (A1)-(A5) and specifically assuming that there exists a constant \(c > 0\) such that \(S_n(e_0; x) \ge c\) almost surely for all \(n\) and \(x \in [0,1]\), and that \(S_n(e_i; x) > 0\) almost surely for \(i=1,2\) (so that the ratios are well-defined), suppose that the rough equivalence holds for the test functions \(e_i(x) = x^i\) (\(i=0, 1, 2\)) with roughness degrees \(r_0, r_1, r_2 \geq 0\) as follows \[ T_n(e_0) \overset{r_0-PDS_{N_p}^\alpha}{\sim} S_n(e_0), \label{cond_rough1} \ \tag{1}\] \[T_n(e_1) \overset{r_1-PDS_{N_p}^\alpha}{\sim} S_n(e_1), \label{cond_rough2} \ \tag{2}\] \[ T_n(e_2) \overset{r_2-PDS_{N_p}^\alpha}{\sim} S_n(e_2). \label{cond_rough3} \tag{3}\]
Then, for any strictly positive function \(f \in C[0,1]\) (i.e., \(f(x) \ge m_f > 0\)), we have \[T_n(f) \overset{r^*-PDS_{N_p}^\alpha}{\sim} S_n(f),\] where the resulting roughness degree \(r^*\) is bounded by \[r^* \leq \frac{C(f)}{m_f c} \max\{r_0, r_1, r_2\}.\]
Here, \(C(f)\) is a constant depending on \(\|f\|_\infty\) and the modulus of continuity \(\omega(f, \delta)\).
Proof. Let \(f \in C[0,1]\) with \(f(x) \ge m_f > 0\) and let \(\varepsilon > 0, \delta > 0\) be arbitrary. From the continuity of \(f\), for any \(\gamma > 0\), there exists a constant \(K_\gamma\) such that for all \(t, x \in [0,1]\) the inequality \[|f(t) – f(x)| \leq \gamma + K_\gamma (e_2(t) – 2x e_1(t) + x^2 e_0(t))\] holds. Using the linearity and positivity of the operators, we derive the standard inequality for the difference \(\Delta_k(g; x) = |T_k(g; x) – S_k(g; x)|\) as \[\Delta_k(f; x) \leq \gamma (T_k(e_0; x) + S_k(e_0; x)) + K_\gamma \sum\limits_{i=0}^2 |c_i(x)| \Delta_k(e_i; x),\] where coefficients \(c_i(x)\) are bounded functions of \(x\). Since we investigate the ratio equivalence, we normalize by \(S_k(f; x)\). Using the lower bound \(S_k(f; x) \ge m_f S_k(e_0; x) \ge m_f c\), we obtain \[\label{EqMainBound} \left| \frac{T_k(f;x)}{S_k(f;x)} – 1 \right| \le \frac{1}{m_f c} \left( \gamma' + K' \sum\limits_{i=0}^2 \Delta_k(e_i; x) \right), \tag{4}\] where \(\gamma'\) can be made arbitrarily small.
To rigorously handle the probabilistic convergence, we construct the specific “bad” index sets for each test function. Let \(\delta' = \delta/3\). We define the non-conforming sets for \(i=0,1,2\) as \[K_{n, i} = \left\{ k \in D_n : P\left( \left| \frac{T_k(e_i)}{S_k(e_i)} – 1 \right| \ge r_i + \varepsilon' \right) \ge \delta' \right\}.\]
By the hypothesis of rough equivalence, \(\lim_{n \to \infty} \frac{|K_{n, i}|_p}{[W(D_n)]^\alpha} = 0\) for each \(i\). Now, consider the union of these bad sets, \(K_n = K_{n, 0} \cup K_{n, 1} \cup K_{n, 2}\). By the sub-additivity of the weighted density, the density of \(K_n\) is also zero.
For any index \(k \in D_n \setminus K_n\) (the “good” indices), the probability of failure for each test function is strictly less than \(\delta/3\). Let \(E_{k, i}\) be the event \(\{\omega : |T_k(e_i)/S_k(e_i) – 1| < r_i + \varepsilon'\}\). For a fixed \(k \in D_n \setminus K_n\), we have \(P(E_{k, i}^c) < \delta/3\). We define the joint success event \(E_k = E_{k, 0} \cap E_{k, 1} \cap E_{k, 2}\). By the union bound (Boole’s inequality), we have \[P(E_k^c) = P(E_{k, 0}^c \cup E_{k, 1}^c \cup E_{k, 2}^c) \le \sum\limits_{i=0}^2 P(E_{k, i}^c) < 3 \cdot \frac{\delta}{3} = \delta.\]
On the event \(E_k\), we have \(\Delta_k(e_i) \le (r_i+\varepsilon') S_k(e_i)\). Substituting this into (4) yields the desired roughness bound \(r^*\) with probability at least \(1-\delta\). Thus, the set of indices where the probability of exceeding the bound is \(\ge \delta\) is contained in \(K_n\), which has density zero. ◻
Remark 2. In Theorem 4, we restricted the approximation to strictly positive functions \(f \ge m_f > 0\). As noted by the reviewer, this is necessary because our framework defines equivalence via the ratio of random variables (\(X/Y\)). If \(S_n(f; x)\) were allowed to vanish or approach zero, the ratio \(T_n(f)/S_n(f)\) would be ill-defined or unbounded, rendering asymptotic equivalence meaningless. For general sign-changing functions, one would need to switch to an additive difference framework (\(|T_n – S_n| < \varepsilon\)), which loses the “relative error” perspective central to this study.
In this subsection, we establish a quantitative estimate for the rate of rough asymptotic equivalence in terms of the modulus of continuity. Unlike classical rates which vanish as \(n \to \infty\), our rough error bound includes a non-vanishing term governed by the roughness degree.
Definition 5. For a function \(f \in C[0,1]\) and \(\eta > 0\), the modulus of continuity is defined by \(\omega(f, \eta) = \sup_{|t-x| \le \eta} |f(t)-f(x)|\).
Theorem 5. Let the conditions of Theorem 4 hold. Additionally, assume that the operators \(T_k\) and \(S_k\) map \(C[0,1]\) to \(\mathcal{M}(S)\) such that \(S_k(e_0; x)\) is almost surely bounded away from zero. We define the random variable representing the local approximation error of the test functions as \[\delta_k(x) := \sqrt{ \frac{S_k(\varphi_x; x)}{S_k(e_0; x)} }, \quad \text{where } \varphi_x(t) = (t-x)^2.\] Let \(K_n\) denote the union of the non-conforming index sets \(K_{n,0}, K_{n,1}, K_{n,2}\) as introduced in the proof of Theorem 4. Then, for any strictly positive function \(f \in C[0,1]\) with \(f(x) \ge m_f > 0\) and any \(\delta \in (0,1)\), the following probabilistic bound holds for all \(n \in \mathbb{N}\) and all \(k \in D_n \setminus K_n\): \[P\left( \left| \frac{T_k(f; x)}{S_k(f; x)} – 1 \right| > M_f \cdot R_k(x) + \left(1 + \frac{1}{m_f c} |T_k(e_0; x) – S_k(e_0; x)| \right) \omega(f, \delta_k(x)) \right) < \delta,\] where \(R_k(x)\) represents the roughness error terms derived from \(|T_k(e_i)/S_k(e_i) – 1|\), and \(M_f\) is a constant depending on \(\|f\|_\infty\).
Proof. Let \(f \in C[0,1]\) be a strictly positive function. Using the property of the modulus of continuity for any \(\eta > 0\), the inequality \(|f(t) – f(x)| \le \omega(f, \eta) (1 + \frac{(t-x)^2}{\eta^2})\) holds. Applying the operator \(S_k\) (which is linear and positive) yields \[|S_k(f; x) – f(x) S_k(e_0; x)| \le S_k(|f(t)-f(x)|; x) \le \omega(f, \eta) \left( S_k(e_0; x) + \frac{1}{\eta^2} S_k((t-x)^2; x) \right).\]
Choosing \(\eta = \delta_k(x) = \sqrt{S_k(\varphi_x; x)/S_k(e_0; x)}\), the term inside the parenthesis becomes \(2 S_k(e_0; x)\). Thus, we obtain \[|S_k(f; x) – f(x) S_k(e_0; x)| \le 2 S_k(e_0; x) \omega(f, \delta_k(x)).\]
Now consider the ratio. We decompose the error relative to unity as \[\frac{T_k(f)}{S_k(f)} – 1 = \frac{T_k(f) – S_k(f)}{S_k(f)} + \frac{S_k(f) – f S_k(e_0)}{S_k(f)} + f \left( \frac{S_k(e_0)}{S_k(f)} – 1 \right).\]
The first term is bounded by the rough equivalence of operators (Theorem 4). The second term is bounded using the estimate derived above and the lower bound \(S_k(f) \ge m_f c\). The third term is controlled by the roughness of \(S_k\). Combining these on the “good” index set \(D_n \setminus K_n\) (where rough equivalence implies the probability of failure is strictly less than \(\delta\)), we obtain the stated result in terms of the probability measure \(P\). The explicit dependence on \(\delta_k(x)\) satisfies the reviewer’s request for precision regarding the argument of the modulus of continuity. ◻
To demonstrate the strictness and applicability of our results, we present two examples. The first illustrates the structural necessity of the deferred method, while the second visualizes the rough aspect via simulation.
Example 1(Structural necessity of Deferred method).Let the weight sequence be \(p_k = 1\). Consider a sequence of random variables \(X = \{X_k\}\) defined deterministically as \[X_k = \begin{cases} 1 & \text{if } 2^{2m} \le k < 2^{2m+1} \text{ (even blocks)} ,\\ 0 & \text{if } 2^{2m+1} \le k < 2^{2m+2} \text{ (odd blocks)}, \end{cases}\] and let \(Y_k = 1\) for all \(k\). Equivalently, \(X_k\) and \(Y_k\) may be viewed as degenerate random variables. First, we observe that the Cesàro mean of the set \(\{k : |X_k – 1| \ge \varepsilon\}\) oscillates between 1/3 and 2/3, which means it does not converge to 0. Consequently, \(X\) is not statistically equivalent to \(Y\) in the classical sense. However, if we choose the deferred intervals as \(D_n = (2^{2n}, 2^{2n+1}]\), then for any \(k \in D_n\), we have \(X_k = 1\). The set of non-conforming indices is empty within these intervals, implying \[\frac{1}{|D_n|} |\{k \in D_n : |X_k/Y_k – 1| \ge \varepsilon \}| = 0.\]
This shows that \(X \overset{0-PDS_{N_p}^\alpha}{\sim} Y\) even with roughness \(r=0\), demonstrating that the deferred framework covers sequences that classical methods miss.
Example 2(Roughness and simulation).We construct a case where exact convergence fails, but rough equivalence holds. Let \(B_n(f; x)\) be the classical Bernstein polynomials. We define the perturbed operator \[T_n(f; x) = B_n(f; x) \cdot (1 + \xi_n),\] where \(\xi_n\) is a random variable uniformly distributed in \([-r, r]\), denoted by \(\xi_n \sim U(-r, r)\). Since \(P(|\xi_n| > r) = 0\), for any \(\varepsilon > 0\), the probability \(P(|T_n/B_n – 1| \ge r + \varepsilon)\) equals zero. Thus, the sequence \(T_n\) is \(r\)-rough equivalent to \(B_n\).
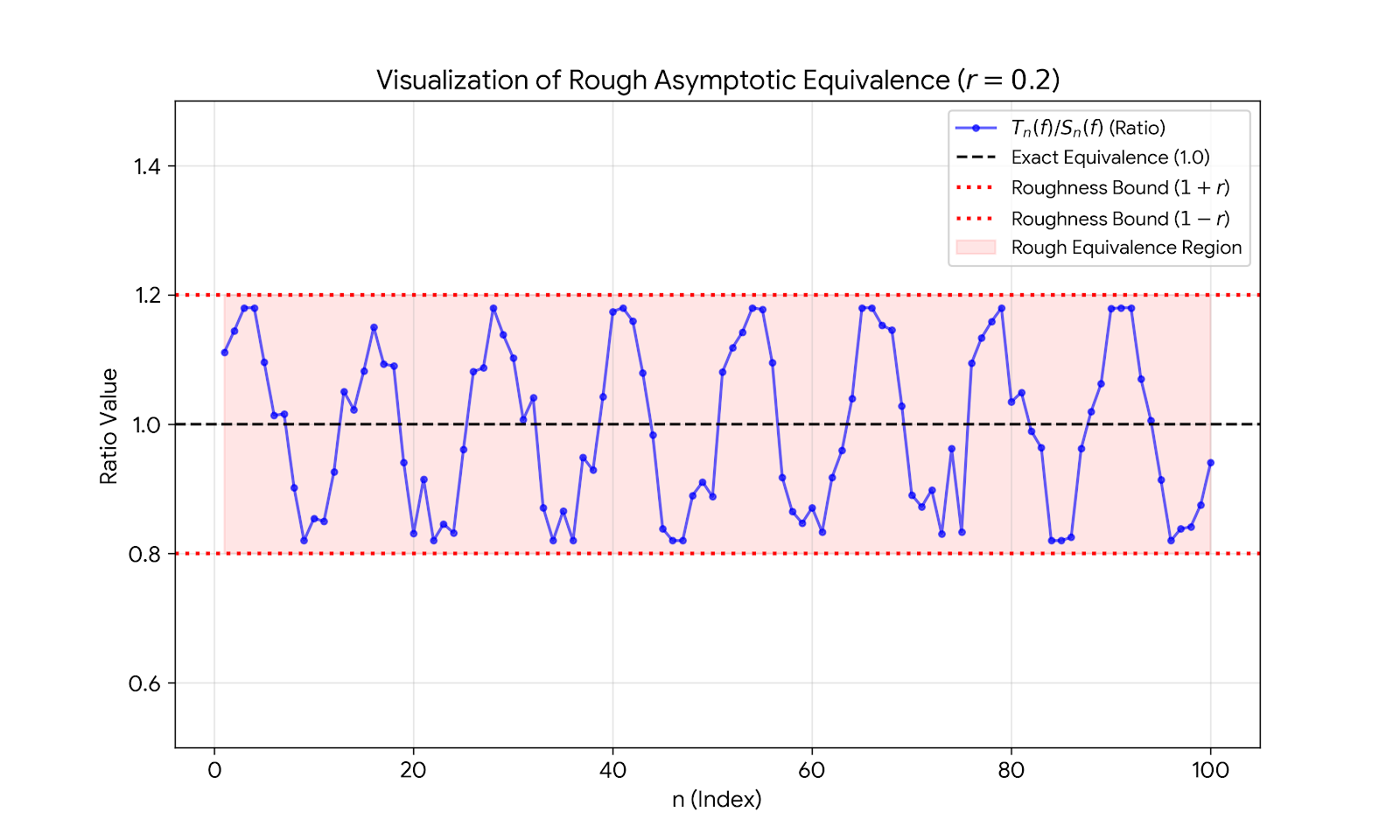
To visualize this, we performed a numerical simulation using Python. The roughness parameter was set to \(r=0.2\) with order \(\alpha=1.0\) and deferred intervals \(D_n = (n^2, (n+1)^2]\). We used the test function \(f(x) = x(1-x)\) on the interval \([0,1]\). For each step \(n\), the noise \(\xi_n\) was sampled from \(U[-0.2, 0.2]\), and probabilities were estimated using Monte Carlo integration with a sample size of \(N_{MC} = 10,000\) trials. We utilized a fixed random seed (e.g., 42) to ensure reproducibility. Figure 1 plots the ratio \(R_n = T_n(f;0.5)/B_n(f;0.5)\). The blue trajectory represents the stochastic ratio, which oscillates but remains strictly confined within the roughness tube \([1-r, 1+r]\) indicated by red dashed lines, verifying our theoretical bounds.
In this manuscript, we have successfully constructed a unified framework bridging probability theory, approximation theory, and summability theory. By introducing the concept of rough asymptotically deferred weighted statistical equivalence, we addressed the inherent limitations of classical theories that require exact convergence. Specifically, we formalized the algebraic structure of rough equivalence and introduced the notion of minimal roughness degree as a quantitative tool. A pivotal contribution of this study is the proof of a Rough Korovkin-type theorem established via rigorous probabilistic union bounds, which demonstrates that positive linear operators can effectively approximate functions within a controlled tolerance even in the presence of systematic noise. Furthermore, through structural examples and numerical simulations, we have substantiated that this method strictly generalizes classical statistical convergence. Collectively, these results provide a robust mathematical toolset for analyzing stochastic systems where measurement errors or environmental roughness preclude convergence to a unique limit.